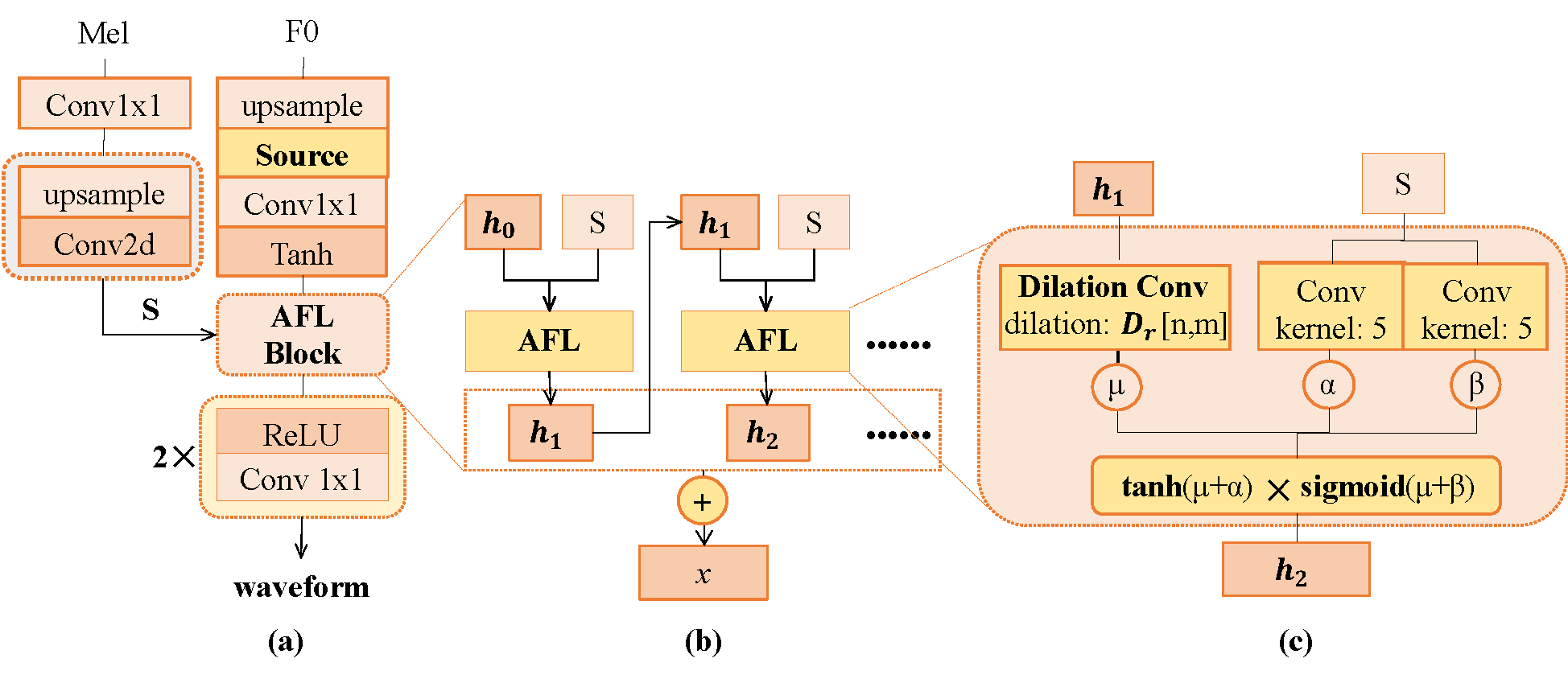
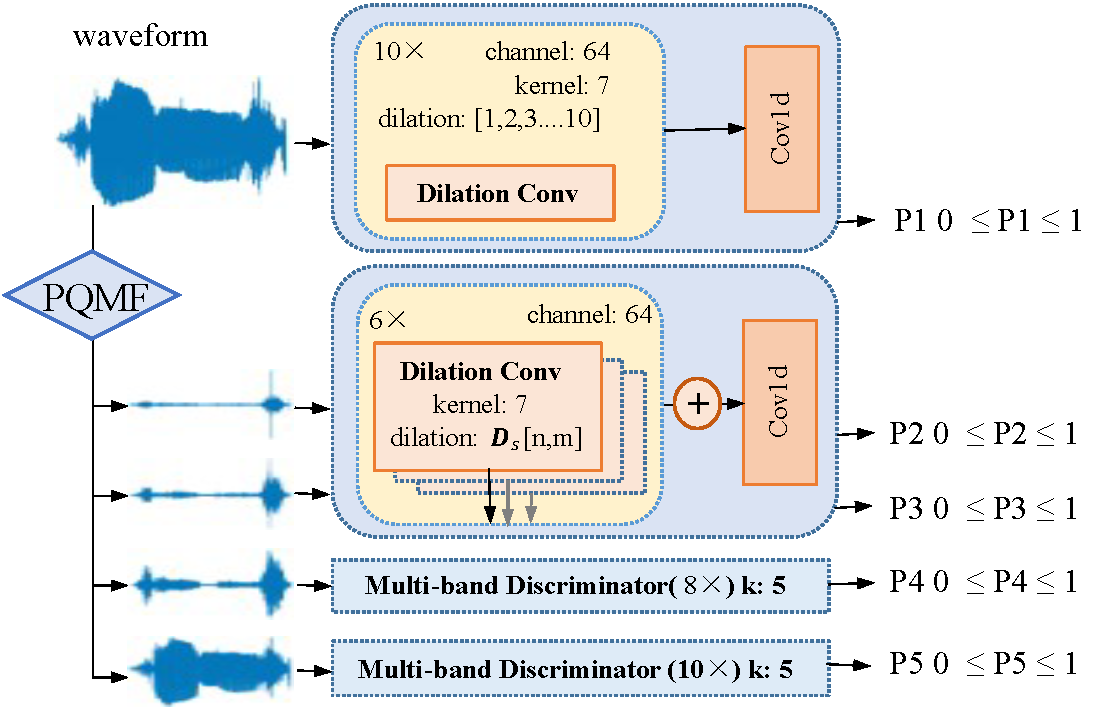
Deep generative models have achieved significant progress in speech synthesis to date, while high-fidelity singing voice synthesis is still an open problem for its long continuous pronunciation, rich high-frequency parts, and strong expressiveness. Existing neural vocoders designed for text-to-speech cannot directly be applied to singing voice synthesis because they result in glitches and poor high-frequency reconstruction. In this work, we propose SingGAN, a generative adversarial network designed for high-fidelity singing voice synthesis. Specifically, 1) to alleviate the glitch problem in the generated samples, we propose source excitation with the adaptive feature learning filters to expand the receptive field patterns and stabilize long continuous signal generation; and 2) SingGAN introduces global and local discriminators at different scales to enrich low-frequency details and promote high-frequency reconstruction; and 3) To improve the training efficiency, SingGAN includes auxiliary spectrogram losses and sub-band feature matching penalty loss. To the best of our knowledge, SingGAN is the first work designed toward high-fidelity singing voice vocoding. Our evaluation of SingGAN demonstrates the state-of-the-art results with higher-quality (MOS 4.05) samples. Also, SingGAN enables a sample speed of 50x faster than real-time on a single NVIDIA 2080Ti GPU. We further show that SingGAN generalizes well to the mel-spectrogram inversion of unseen singers, and the end-to-end singing voice synthesis system SingGAN-SVS enjoys a two-stage pipeline to transform the music scores into expressive singing voices.
Audio samples are available at https://SingGAN.github.io, and we will release our code and pre-trained model in the future.